
A few months ago I came to the conclusion that our approach to security event monitoring was flawed. Traditional alert-based systems generate low fidelity indications of compromise and make a lot of work for SecOps triage teams. On the other hand, UEBA based systems fair no better. If their output is fed into alert systems then they actually make the problem worse and on the few occasions where a risk based workflow is in use by the SOC, they simply give you a starting point as a nudge in what is possibly the right direction. After that the SOC workflow is the same, regardless of what type of SIEM system you use. You spend all of your time in the Search interface so you really should buy a SIEM with the best possible search UI and query language because you are going to get to know it very well.
I decided at that point that any kind of analytics based approach needed to support the search workflow rather than adding to the alert noise. What I wanted was a system which improved my search results and naturally lead me from search to search until I have something actionable. I needed a system that told me what in my search results I should be looking at and what was anomalous about it…
At about this time I was also dealing with another challenge. More and more SOC teams were asking for a UEBA based system which they could overlay upon existing data lakes without having to go through the hassle of ingesting the data again. Ideally it should overlay on multiple data lakes at once and allow hybrid search. I was well rehearsed in the response to this. The first part of which went along the lines of “You have to move the processing to the data or the data to the processing…”. So rehearsed was I that I trotted this line out without giving it much thought. It didn’t satisfy anyone.
Then one day whilst out on a run I had an epiphany. Running is where I let my brain solve difficult problems as I sweat the frustration out of me! I realised that actually these two problems were connected and that the same solution fixed both problems. And what was better I had an idea of what that solution looked like! I finished my run and went home (I run in a local forest as my little narrow country lanes are really not safe).
The shape of a solution
What I needed to be able to do to solve the search problem was to be able to take any search result and identify anomalies in it. That is really what the SOC analyst is doing anyway, I just needed to make my SIEM help. Anomalies are just that; and the best way to identify them is by clustering the results. Because I am just clustering the results of a search I don’t actually need to worry too much about the nature of the data. If I can build the cluster then I can find outliers. I already knew how to do that from some previous work I had done with Self Organising Maps but I knew that algorithm was much too slow. I looked around and found a high-speed clustering algorithm called UMAP which stands for Uniform Manifold Approximation and Projection which is a dimensionality reduction approach much like SOM. Betyter yet there were python libraries waiting to be imported!
But what to cluster on? Well the answer to that came from my desire to avoid the expensive ingestion, parsing normalisation and analytics pipeline of traditional UEBA based SIEMS. In fact if I was looking at search results then I could assume that the data was already parsed and normalised. I was in fact looking at the analytics overlay to existing data-lakes problem. So how to get a handle on something to cluster on which was fast enough for real-time search?
Fortunately, I had just finished a RAG project for LLMs. For the un-initiated, that is a Retrieval Augmented Generation for Large Language Models. We do love our acronyms in tech don’t we! In that project I had been taking large amounts of text (emails) and breaking them down into short runs and then generating vectorisations. Effectively creating a tensor which “represented” their semantic meaning. I realised I could do the same with log lines, or more correctly for each line of the returned search results.
My initial though was that I could do this as a sort of pre-parse of the entire data lake and store the results either in the original data lake itself or in a vector database. Only later did I enhance this to avoid this lengthy initial step and instead generated the vectors on-the-fly for each search result obtained. Once I had the vectorisation for the individual results it is a simple matter to use UMAP to generate clusters for me and then identify outliers to those clusters, i.e. results which stand out from the overall pattern.
To begin with I had used Ollama running on a server in my home lab. This was a good idea but set me back quite a bit. I managed to tickly a bug in Ollama where batch mode generates erroneous, or at least not very accurate results. It is also not much quicker that generating individual embeddings. I also had a pretty old GPU in the server and so the process of generating good vector embeddings was very slow. I eventually changed to using a machine with a built in GPU – an Nvidia 3060 so about as low end as it is possible to buy right now and instead of Ollama I used JAX (A super fast python library which can take advantage of GPUs) to generate the embeddings directly on box. The speed-up was phenomenal and make the real time calculation of vectors possible.
My test data was security logs, predominantly generated from Microsoft. I gave the system groups of entries to calculate, simulating different searches returning results from just a few to several hundered results. I was able to generate the embeddings and calculate clusters and outliers in at most 4 seconds, even for quite large search results (all of the time was taken in the generation of the embeddings rather than in UMAP). I think by using Redis or similar to cache results I could significantly improve the performance, particularly as searches tend to be iterative with the same results being returned each time as the search is narrowed down.
Things I learned along the way
UMAP is great. Given that I don’t know in advance how many clusters there might be; many clustering algorithms are ruled out. And there might be a lot of clusters indeed. It is also very fast, but it can tend to make it harder to find outliers as it does tend to reduce the distance between points. I think a little tuning and I can resolve that but a data scientist might offer alternative approaches. I think I could also improve how I identify outliers.
The clustering works regardless of the data, in fact it seems to work whether the data is parsed or not, with only minor changes to its accuracy. I used a standard vectorisation model and got really impressive results. The vectors were all 768 bytes in size. Another reason not to precalculate them for the entire data lake! Some analysis suggested that the manifold the log data sits on is much smaller than the 768 bytes of the standard vector. I think if I were to build my own model I could reduce the vector size to below 400 bytes both saving space and making the calculation much faster. The challenge with that is that I would need an awful lot of log data.
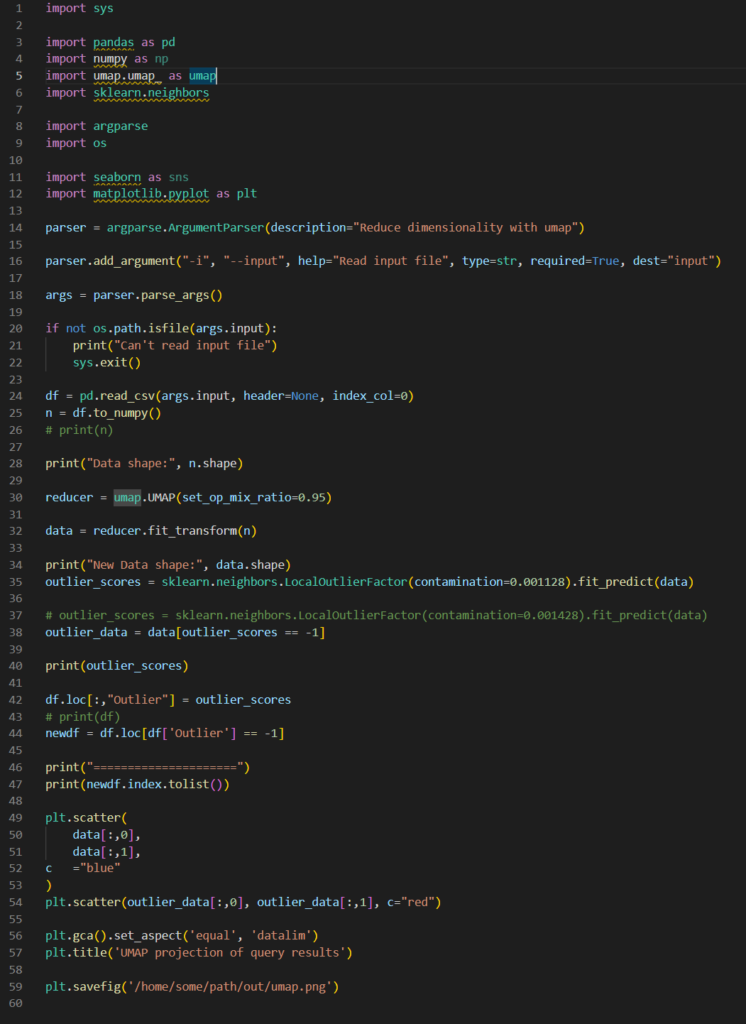
I am not sure if this general approach would work effectively across multiple data lakes with different normalisation schema. OCSF (Open Cybersecurity Schema Framework) may actually be an important element in making this workable across multiple security lakes! Some investigation is certainly warranted here.
The last real problem is the explainability. I can easily identify outliers but explaining why they are outliers is impossible (for a machine) as the algorithm itself does not understand the data. A normal UEBA system uses statistical methods (as opposed to neual networks) to identify anomalies and it is easy to work back, look at baselines and by how much the are exceeded etc. I think the thing to do here is to have the SOC analyst select the fields to cluster on (all of them is the obvious default) but if the analyst narrows down the clustering then the results should be more self evident. As an example, if the search is for everyone who logged into a machine over the last month then the clustering could be narrowed down to use name, source address and possible a few other criteria. Any flagged anomalies would form the basis for a new search to establish why they are anomalous.
Generating the cluster relies upon there being some form of semantics to what is being clustered. Fields like username or machine name or domain work very well here. Time does not work. For clustering based upon time some pre work may be needed if only to create buckets for the data. Login time in ten-minute buckets can be clustered were as times which vary by milliseconds cannot. Similarly, IP addresses can be clustered but not really effectively. Ideally you would preprocess those into subnets. The vectorisation itself is unable to do that so every IP address is as unique as every other one and even internal and external ones tend to be treated the same. Definite preprocessing required for IP addresses, if only to convert them into domain names and identify them as internal or external.
To turn this into something usable I’d need to hook into the search interface of an existing Data Lake and grab the returned results. I can then calculate the clusters and identify anomalies and pass the results on to the UI with anomalies highlighted. Ideally, I’d let the search results display and then have the anomalies added as and when they are ready (given that there might be a few seconds delay). I’m really not a GUI type of a person so I’ll leave that for someone else.
Summary
Despite what I have been telling people; it is perfectly possible to overlay analytics on existing data lakes without ingesting the data into a costly UEBA SIEM and storing the data again in yet another cloud platform. The concept is proven but there is work to be done. Pre calculating the vectors brings with it interesting opportunities for new types of search. The similarity search. “Show me logins like this one” for instance might give more power to over worked SOC teams. Though the pre calculation smacks or reingestion so that may be a step too far.
The advantage of this approach is that it moved the analytics into the Search workflow and keeps it relevant through the majority of the SOC investigation workflow. This does require TPU or GPU enhanced hardware to be effective, but we really need to be developing SIEM technology for the next generation SOC not the last one.